Quickstart Evaluation
Evaluate the quality of your LLM App with Lynxius in just one minute! Ship AI with confidence following this quickstart guide.
Signup for free here to create an account. Don't forget to validate your email!
Install Lynxius library
Install Lynxius Python library locally, or on your server.
pip install lynxius
Create Your First Project and API Key
Create your first project and create an API Key for it to start your LLM evaluations. Rememeber to store your secret key somewhere safe, you won't be able to access to its value anymore.
Use the newly generated secret key to set up your project API key locally, or on your server, to start your LLM evaluations.
export LYNXIUS_API_KEY='your-api-key-here'
export LYNXIUS_API_KEY='your-api-key-here'
set LYNXIUS_API_KEY "your-api-key-here"
Select Evaluation Setup
Remote vs Local Evaluations
The Lynxius remote evaluation setup is a fully managed service where the API keys for the models used in testing are provided and managed by the Lynxius team. Evaluation tasks are executed in the background, freeing you from delays and compute costs.
The Lynxius local evaluation setup is convenient if you prefer to use your OpenAI free credits and are comfortable managing the API keys for the models used in testing.
If you plan to run evaluations remotely, you can skip to Run Evals Remotely. If you prefer to run evaluations locally, make sure your OpenAI API key is set in your environment.
export OPENAI_API_KEY='your-api-key-here' # only needed to run evals locally
export OPENAI_API_KEY='your-api-key-here' # only needed to run evals locally
set OPENAI_API_KEY "your-api-key-here" :: only needed to run evals locally
Run Evaluations
We want to use Answer Correctness and Semantic Similarity evaluators from our library to evaluate the quality of the chat_pizza LLM APP.
# import test dataset
# `chat_pizza` LLM App used OpenAI GPT-4 to produce its outputs (https://github.com/lynxius/lynxius-docs/blob/main/docs/public/images/)
dataset = [
{
"query": "What is the first tomato-topped pizza? Keep it short.",
"reference": (
"Pizza marinara is supposedly the oldest tomato-topped pizza."
),
"output": (
"The first tomato-topped pizza is the Margherita, created in "
"1889 in Naples, Italy."
),
},
{
"query": "When did pizza arrive in the United States? Keep it short.",
"reference": (
"The first pizzeria in the U.S. was opened in New York City's "
"Little Italy in 1905."
),
"output": (
"Pizza arrived in the United States in late 19th century, brought "
"by Italian immigrants."
),
},
{
"query": "Which tomato sauce is used in neapolitan pizza? Keep it short.",
"reference": (
"The tomato sauce of Neapolitan pizza must be made with San Marzano "
"tomatoes or pomodorini del Piennolo del Vesuvio."
),
"output": (
"San Marzano tomatoes are traditionally used in Neapolitan pizza "
"sauce."
),
}
]
# start evaluating!
from lynxius.client import LynxiusClient
from lynxius.evals.answer_correctness import AnswerCorrectness
from lynxius.evals.semantic_similarity import SemanticSimilarity
client = LynxiusClient()
# add tags for frontend filtering
label = "PR #111"
tags = ["GPT-4", "chat_pizza", "q_answering", "PROD", "Pizza-DB:v2"]
answer_correctness = AnswerCorrectness(label=label, tags=tags)
semantic_similarity = SemanticSimilarity(label=label, tags=tags)
for entry in dataset:
answer_correctness.add_trace(
query=entry["query"],
reference=entry["reference"],
output=entry["output"],
context=[]
)
semantic_similarity.add_trace(
reference=entry["reference"],
output=entry["output"],
context=[]
)
client.evaluate(answer_correctness)
client.evaluate(semantic_similarity)
# import test dataset
# `chat_pizza` LLM App used OpenAI GPT-4 to produce its outputs (https://github.com/lynxius/lynxius-docs/blob/main/docs/public/images/)
dataset = [
{
"query": "What is the first tomato-topped pizza? Keep it short.",
"reference": (
"Pizza marinara is supposedly the oldest tomato-topped pizza."
),
"output": (
"The first tomato-topped pizza is the Margherita, created in "
"1889 in Naples, Italy."
),
},
{
"query": "When did pizza arrive in the United States? Keep it short.",
"reference": (
"The first pizzeria in the U.S. was opened in New York City's "
"Little Italy in 1905."
),
"output": (
"Pizza arrived in the United States in late 19th century, brought "
"by Italian immigrants."
),
},
{
"query": "Which tomato sauce is used in neapolitan pizza? Keep it short.",
"reference": (
"The tomato sauce of Neapolitan pizza must be made with San Marzano "
"tomatoes or pomodorini del Piennolo del Vesuvio."
),
"output": (
"San Marzano tomatoes are traditionally used in Neapolitan pizza "
"sauce."
),
}
]
# start evaluating!
from lynxius.client import LynxiusClient
from lynxius.evals.answer_correctness import AnswerCorrectness
from lynxius.evals.semantic_similarity import SemanticSimilarity
client = LynxiusClient(run_local=True) # run evals locally
# add tags for frontend filtering
label = "PR #111"
tags = ["GPT-4", "chat_pizza", "q_answering", "PROD", "Pizza-DB:v2"]
answer_correctness = AnswerCorrectness(label=label, tags=tags)
semantic_similarity = SemanticSimilarity(label=label, tags=tags)
for entry in dataset:
answer_correctness.add_trace(
query=entry["query"],
reference=entry["reference"],
output=entry["output"],
context=[]
)
semantic_similarity.add_trace(
reference=entry["reference"],
output=entry["output"],
context=[]
)
client.evaluate(answer_correctness)
client.evaluate(semantic_similarity)
View Results
Click on the Eval Run link of your project to explore the output of your evaluation. The Eval Runs page reports the average scores of each metric over the entire test dataset. Result UI Screenshot tabs below shows the result on the UI, while the Result Values provide an explanation.
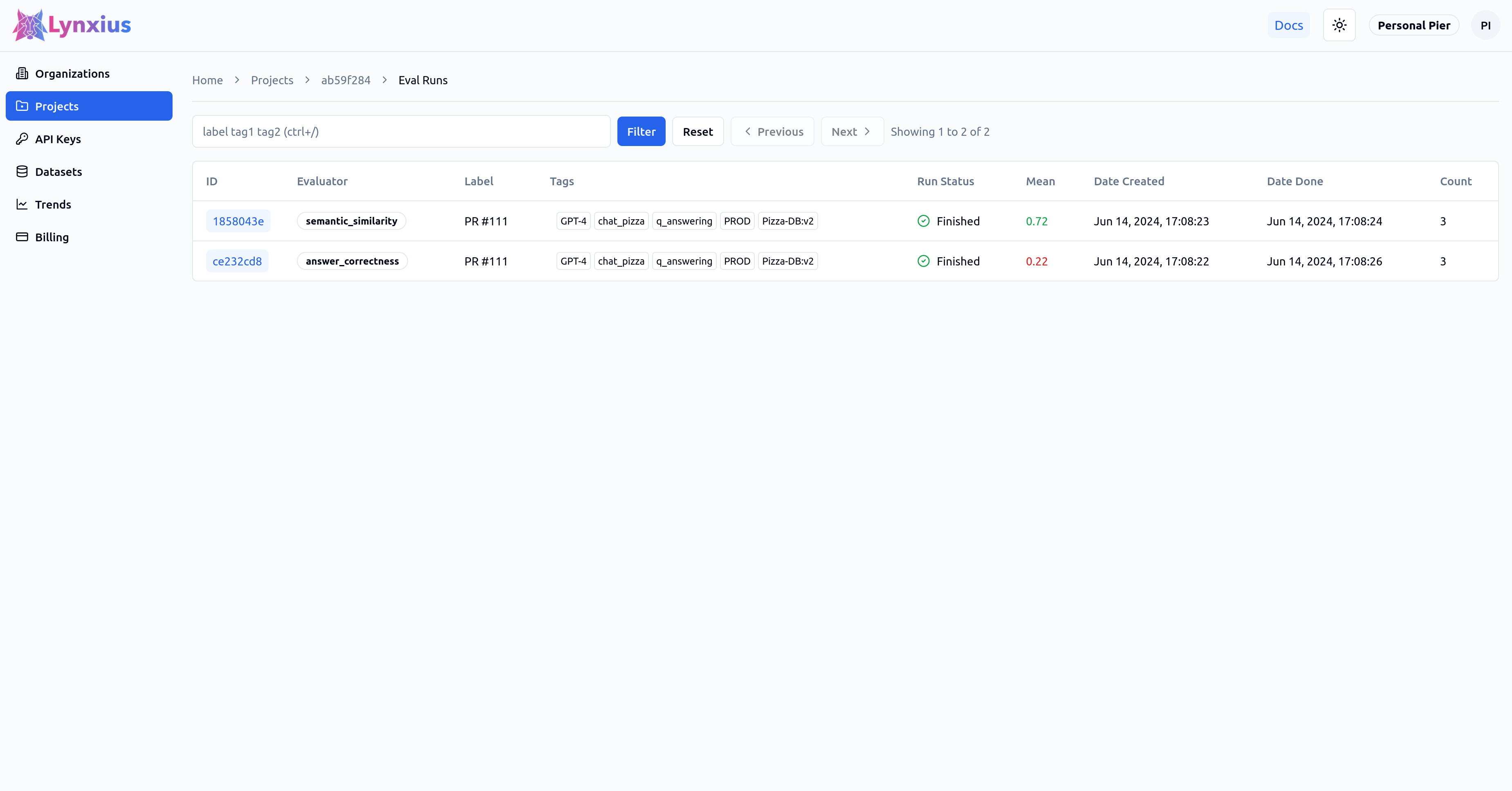
| Evaluator | Aggregated Value | Interpretation |
|---|---|---|
| Semantic Similarity | 0.72 | On average, the output is semantically similar to the reference across the input dataset. |
| Answer Correctness | 0.22 | On average, the output is minimally correct when compared to the reference across the input dataset. |
Click on the Answer Correctness entry on the Eval Runs page for more granular information on the score of each dataset row. The last row result is described below.
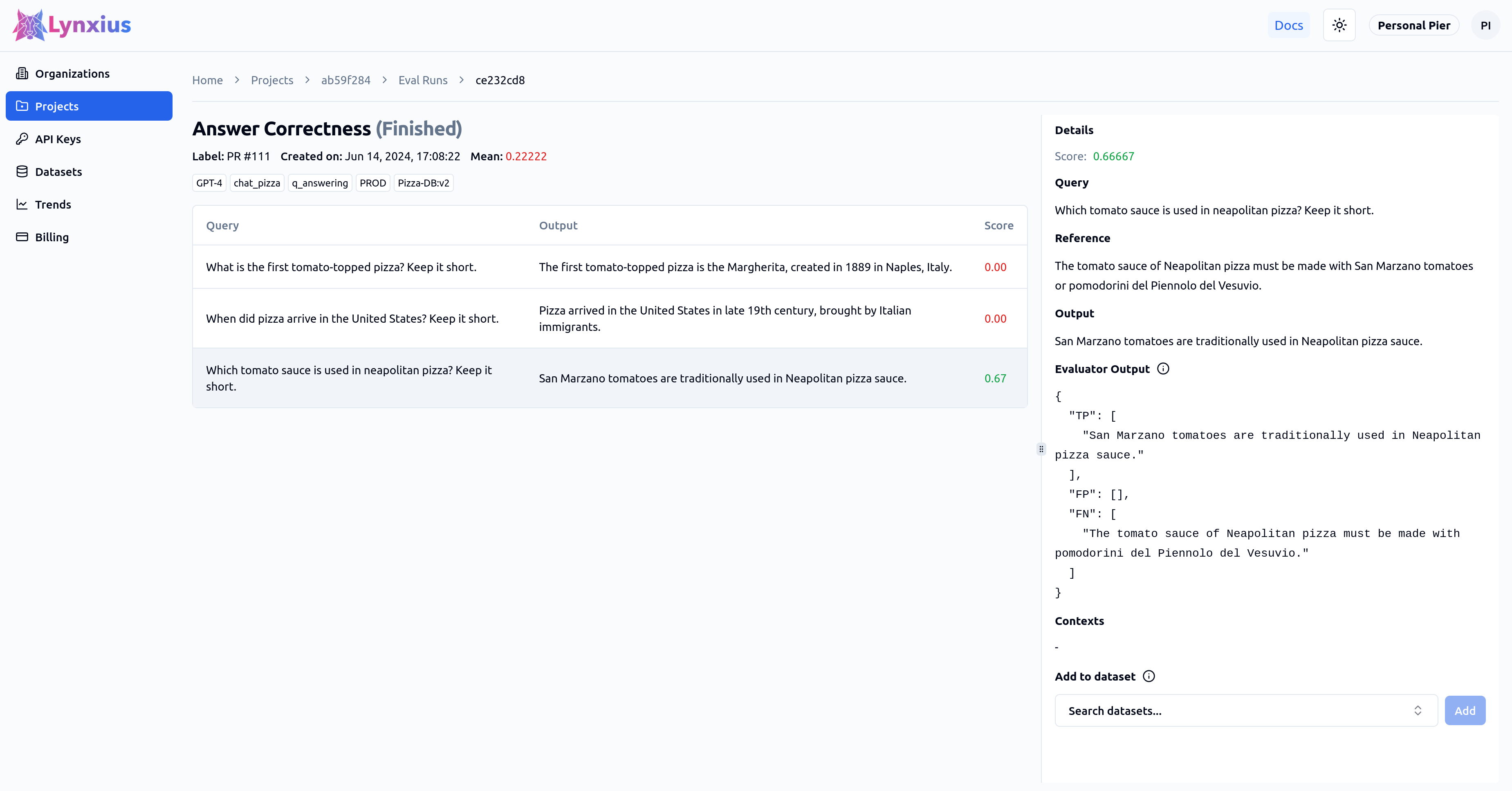
| Score | Value | Interpretation |
|---|---|---|
| Score | 0.66667 | The output is only partially correct when compared to the reference. |
| Evaluator Output |
|
One True Positives and one False Negative have been detected. |
Click on the Semantic Similarity entry on the Eval Runs page for more granular information on the score of each dataset row. The last row result is described below.
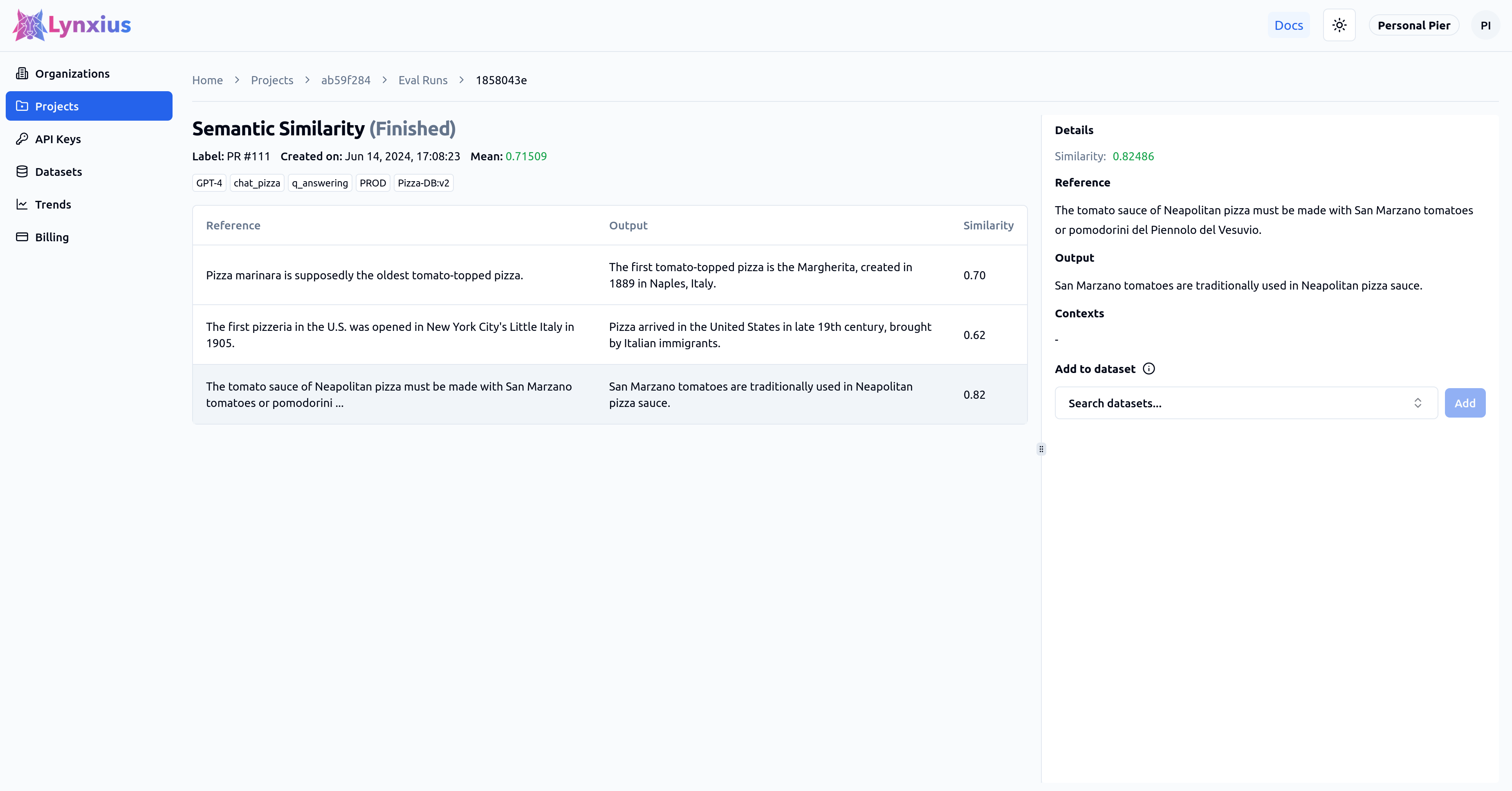
| Evaluator | Aggregated Value | Interpretation |
|---|---|---|
| Similarity | 0.82486 | The output is semantically similar to the reference, although the output omits mentioning the second type of tomatoes allowed, "pomodorini del Piennolo del Vesuvio." |
Conclusion
chat_pizza average Semantic Similarity over the input test dataset is 0.72, however the average Answer Correctness over the input test dataset is only 0.22.
It's time to roll up our sleeves and improve the quality of chat_pizza LLM App! See how on our blog post article.