Custom Evaluator
Custom Evaluator is a versatile, user-defined evaluator that takes a prompt as input and can evaluate any logic specified in the prompt, making it ideal for tasks that require evaluating ad-hoc use cases or business-specific requirements. It accepts a generated answer and arbitrary input arguments, returning True if these align with the prompt logic, and False otherwise.
Calculation
The Custom Evaluator is designed for a wide range of evaluation tasks based on the provided prompt. It interprets the prompt_template along with the values input dictionary, performing the required assessments. The evaluator returns a binary score (True or False) based on how well the inputs align with the specified criteria in the prompt.
Example
Tip
Please consult our full Swagger API documentation to run this evaluator via APIs.
# When using CustomEval make sure that the final verdict is printed at the very
# bottom of the resonse, with no other characters
IS_SPICY_PIZZA="""
You need to evaluate if a pizza description matches a given spiciness level
and vegetarian indication. If both match, the verdict is 'correct'; otherwise,
it's 'incorrect'. Provide a very short explanation about how you arrived to
your verdict. The verdict must be printed at the very bottom of your response,
on a new line, and it must not contain any extra characters.
Here is the data:
***********
Candidate answer: {output}
***********
Spiciness level: {spicy}
***********
Vegetarian indication: {vegetarian}
"""
from lynxius.client import LynxiusClient
from lynxius.evals.custom_eval import CustomEval
client = LynxiusClient()
# add tags for frontend filtering
label = "PR #111"
tags = ["GPT-4", "chat_pizza", "spiciness", "PROD", "Pizza-DB:v2"]
name = "pizza_spiciness"
custom_eval = CustomEval(label=label, name=name, tags=tags, prompt_template=IS_SPICY_PIZZA)
custom_eval.add_trace(
# output from OpenAI GPT-4 (https://github.com/lynxius/lynxius-docs/blob/main/docs/public/images/hawaiian_pizza_gpt4_output.png)
values={
"output": "Hawaiian pizza: tomato sauce, pineapple and ham.",
"spicy": "Not spicy",
"vegetarian": "NO"
}
)
client.evaluate(custom_eval)
Click on the Eval Run link of your project to explore the output of your evaluation. Result UI Screenshot tab below shows the result on the UI, while the Result Values provides an explanation.
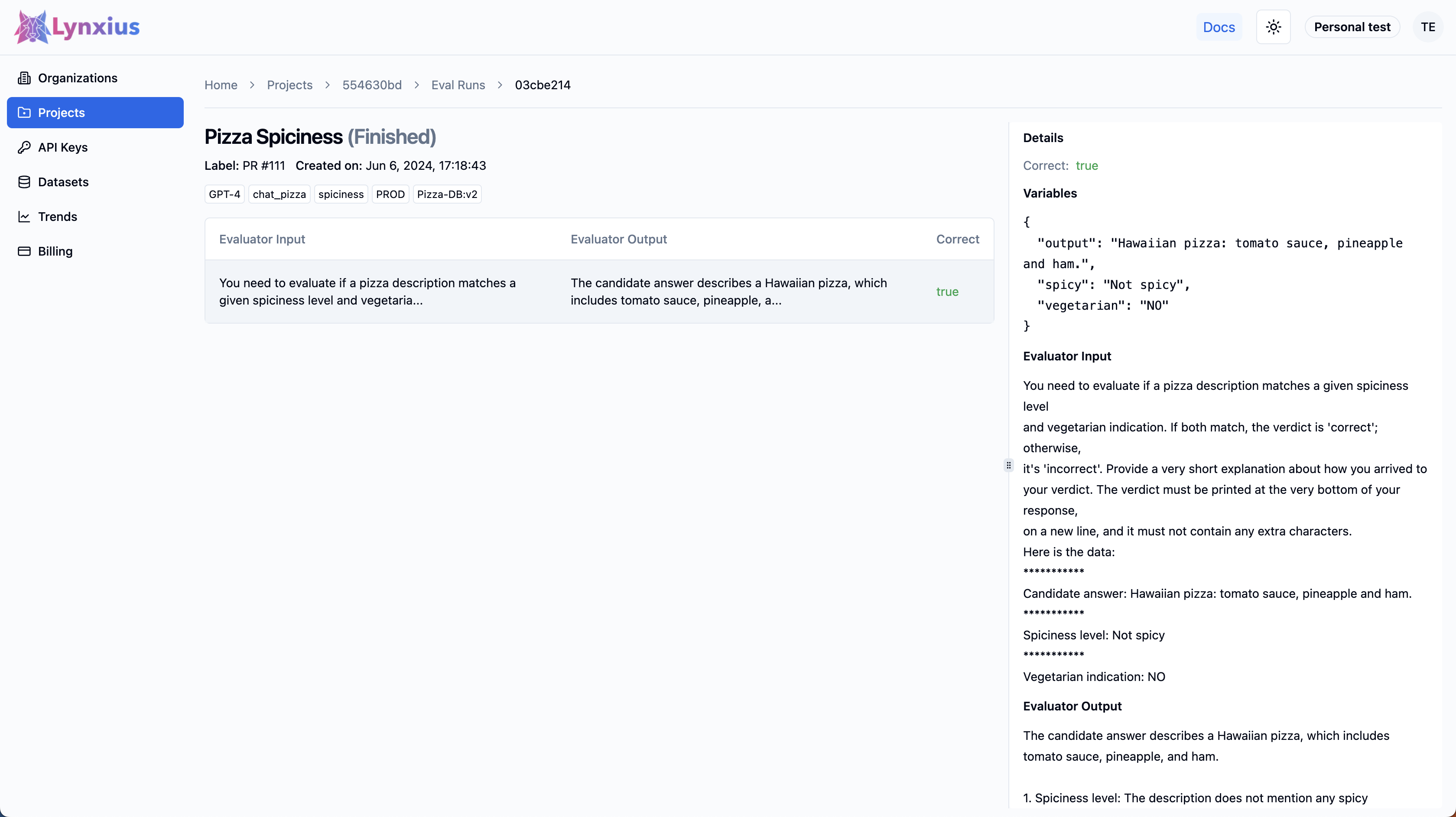
| Score | Value | Interpretation |
|---|---|---|
| Correct | true | The input dictionary (composed of output, spicy and vegetarian) alignes with the specified criteria in the prompt_template. |
| Evaluator Output | The candidate answer describes a Hawaiian pizza with ingredients including ham, which is not vegetarian. The spiciness level is not mentioned, but since it is a Hawaiian pizza, it is typically not spicy. The given spiciness level is "Not spicy" and the vegetarian indication is "NO". Both conditions match the description.correct | The verdict is correct and is printed at the very bottom, after a short explanation about how the LLM model arrived to the this conclusion. |
Inputs & Outputs
| Args | |
|---|---|
| label | A str that represents the current Eval Run. This is ideally the number of the pull request that run the evaluator. |
| href | A str representing a URL that gets associated to the label on the Lynxius platform. This ideally points to the pull request that run the evaluator. |
| tags | A list[str] of tags for filtering on UI Eval Runs. |
| prompt_template | A str containing the evaluation logic to be applied to the arbitrary input texts in the variables dictionary. Each input text should be enclosed within { and } brackets. Ensure that the final verdict is printed at the very bottom of the response, with no additional characters. |
| name | An Optional[str] that will (if provided) be used to override the default name of custom_eval in the Lynxius online platform. This makes it easier to differentiate custom evaluators if you have multiple of them. |
| data | An instance of VariablesContextsPair. |
| Returns | |
|---|---|
| uuid | The UUID of this Eval Run. |
| score | A bool indicating the alignment of the arbitrary input texts in the variables dictionary with the prompt_template logic. Returns True if they align, False otherwise. |