JSON Difference
JSON Difference evaluates the similarity of two JSON objects, making it ideal for tasks like assessing generated structured data to ingest into systems and end-to-end system testing. It uses normalized differences for numeric types (integers, floats, and booleans) and Levenshtein distance for strings to provide a similarity score. This approach captures the semantic meaning of the text, unlike traditional metrics that rely on exact matches.
Calculation
The JSON Difference evaluator calculates the similarity score between corresponding numeric values, or strings, in the reference and output objects. The similarity score is computed using the normalized difference for numeric values and the normalized Levenshtein distance for strings. The score is adjusted based on provided weights for each key, allowing certain keys to have more influence on the final score.
The JSON Difference computation involves the following steps:
- Weight Extraction: Each JSON key can have a weight to define its importance relative to other keys at the same level. Weight is a floating point value between
[0.0, 1.0], where1.0indicates highest importance and0.0means the key doesn't contribute to the overall score. If no weight is provided, default value is1.0. For keys representing complex structures, the weight is specified by a nested element with the same key name prefixed by "__" called "loopback weight". - Normalized Difference Calculation: For numeric values, compute the normalized difference.
- Levenshtein Distance Calculation: For strings, compute the normalized Levenshtein distance.
- Dictionary Comparison: For dictionaries, recursively compare keys and values, combining scores.
- List Comparison: For lists, compare corresponding elements and compute the average score.
- Weighted Average Score: Calculate the weighted average score for all keys.
The formulas for normalized difference \( d \), normalized Levenshtein distance \( l \) and overall similarity score \( S \) are as follow:
where:
- \( x_1 \) and \( x_2 \) are two numeric vaules.
- \( s_1 \) and \( s_2 \) are two strings.
- \(\text{Levenshtein}(s_1, s_2)\) is the Levenshtein distance between the two strings.
- \(\text{len}(s_1)\) and \(\text{len}(s_2)\) are the lengths of the strings.
- \( \sigma_i \) is the score for key \( i \)
- \( w_i \in [0.0, 1.0]\) is the weight for key \( i \)
- \( f \) is the normalization factor to ensure weights sum to \( \text{len}(n) \)
- \( n \) is the total number of keys
Example
Tip
Please consult our full Swagger API documentation to run this evaluator via APIs.
from lynxius.client import LynxiusClient
from lynxius.evals.json_numeric import JsonDiff
client = LynxiusClient()
# add tags for frontend filtering
label = "PR #111"
tags = ["GPT-4", "chat_pizza", "payload_generation", "PROD", "Pizza-DB:v2"]
json_diff = JsonDiff(label=label, tags=tags)
json_diff.add_trace(
# reference from 'NAPIZZA SF (https://github.com/lynxius/lynxius-docs/blob/main/docs/public/images/napizza_san_francisco_menu.png)
reference={
"margherita": 19.0,
"pepperoni": 21.0,
"beer": 6.0,
"fixed_menus": [
{
"menu_name": "baby",
"pizza": "margerita",
"drink": "Coca-Cola",
"price": 24.0,
},
{
"menu_name": "adult",
"pizza": "pepperoni",
"drink": "beer",
"price": 27.0,
}
]
},
# output from PizzaMenu LLM App
output={
"margherita": 39.0,
"pepperoni": 21.0,
"beer": 6.0,
"fixed_menus": [
{
"menu_name": "baby",
"pizza": "margerita",
"drink": "Coca-Cola",
"price": 24.0,
},
{
"menu_name": "adult",
"pizza": "peppers",
"drink": "beer",
"price": 27.0,
}
]
},
weights={
"margherita": 1.0, # getting the pizza wrong is bad!
"pepperoni": 1.0, # getting the pizza wrong is bad!
"beer": 0.25, # getting the beer wrong is ok...
"fixed_menus": {
"__fixed_menus": 0.8, # loopback weight to the fixed_menus list itself
"menu_name": 0.0, # menu_name is not an important key at all
"pizza": 0.5,
"drink": 0.5,
"price": 1.0, # price is the most important thing in the menu!
}
}
)
client.evaluate(json_diff)
Click on the Eval Run link of your project to explore the output of your evaluation. Result UI Screenshot tab below shows the result on the UI, while the Result Values provides an explanation.
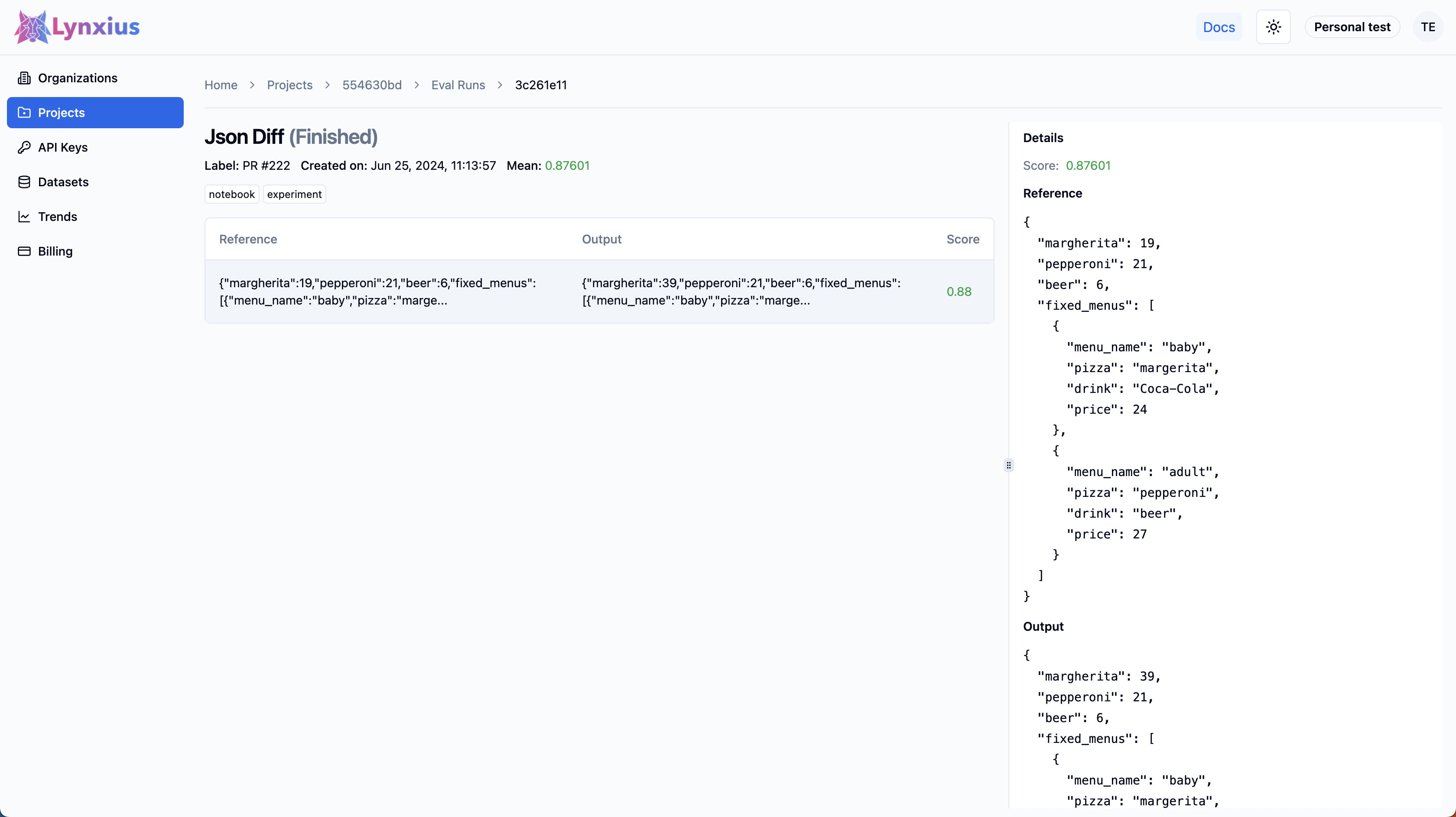
| Score | Value | Interpretation |
|---|---|---|
| Score | 0.87601 | The output is numerically and textually similar to the reference, considering differences in numeric values (int, float, and bool) and string values. The Example Score Calculation can be found at he bottom of this page. |
Inputs & Outputs
| Args | |
|---|---|
| label | A str that represents the current Eval Run. This is ideally the number of the pull request that run the evaluator. |
| href | A str representing a URL that gets associated to the label on the Lynxius platform. This ideally points to the pull request that run the evaluator. |
| tags | A list[str] of tags for filtering on UI Eval Runs. |
| data | An instance of ReferenceOutputWeightsTriplet. |
| Returns | |
|---|---|
| uuid | The UUID of this Eval Run. |
| score | A float in the range [0.0, 1.0] that quantifies the overall similarity between the reference and output considering both numeric and string values. A score of 1.0 indicates perfect similarity, while a score of 0.0 indicates no similarity. |
Example Score Calculation
The table below represents the steps to calculate the Score of 0.87601 returned for the Example above.
| Key | reference |
output |
weights |
\(d\) | \(l\) | \(f\) | \(S\) |
|---|---|---|---|---|---|---|---|
| score | 1.31147 | \( 0.87601 = \frac{(0.65517 \cdot 1.0 \cdot 1.3114)(1.0 \cdot 1.0 \cdot 1.3114)(1.0 \cdot 0.25 \cdot 1.3114)(0.958 \cdot 0.8 \cdot 1.3114)}{4} \) | |||||
| margherita | 19.0 | 39.0 | 1.0 | 0.65517 | - | - | |
| pepperoni | 21.0 | 21 .0 | 1.0 | 1.0 | - | - | |
| beer | 6.0 | 6 .0 | 0.25 | 1.0 | - | - | |
| fixed_menus | 0.8 | \( 0.958 = \frac{1.0 + 0.916}{2} \) | |||||
| fixed_menus[0] | 2.0 | \( 1.0 = \frac{(1.0 \cdot 0.0 \cdot 2.0)+(1.0 \cdot 0.5 \cdot 2.0)+(1.0 \cdot 0.5 \cdot 2.0)+(1.0 \cdot 1.0 \cdot 2.0)}{4} \) | |||||
| menu_name | baby | baby | 0.0 | - | 1.0 | - | |
| pizza | margerita | margerita | 0.5 | - | 1.0 | - | |
| drink | Coca-Cola | Coca-Cola | 0.5 | - | 1.0 | - | |
| price | 24.0 | 24.0 | 1.0 | 1.0 | - | - | |
| fixed_menus[1] | 2.0 | \( 0.916 = \frac{(1.0 \cdot 0.0 \cdot 2.0)+(0.666 \cdot 0.5 \cdot 2.0)+(1.0 \cdot 0.5 \cdot 2.0)+(1.0 \cdot 1.0 \cdot 2.0)}{4} \) | |||||
| menu_name | adult | adult | 0.0 | - | 1.0 | - | |
| pizza | pepperoni | peppers | 0.5 | - | 0.66666 | - | |
| drink | beer | beer | 0.5 | - | 1.0 | - | |
| price | 27.0 | 27.0 | 1.0 | 1.0 | - | - |