Quickstart Continuous Evaluation
Info
This set-up is conceived for a GitHub Action workflow, but is easily transferable to other CI/CD pipelines.
Set up your LLM App Baselines and automated testing pipeline in just three minutes! Ship AI with confidence at every development stage by following this quickstart guide.
In this guide, you will learn how to automatically compare Evaluators' scores of each PR (Pull Request) against your Main-Branch Baseline to decide whether to merge the new code into the main branch.
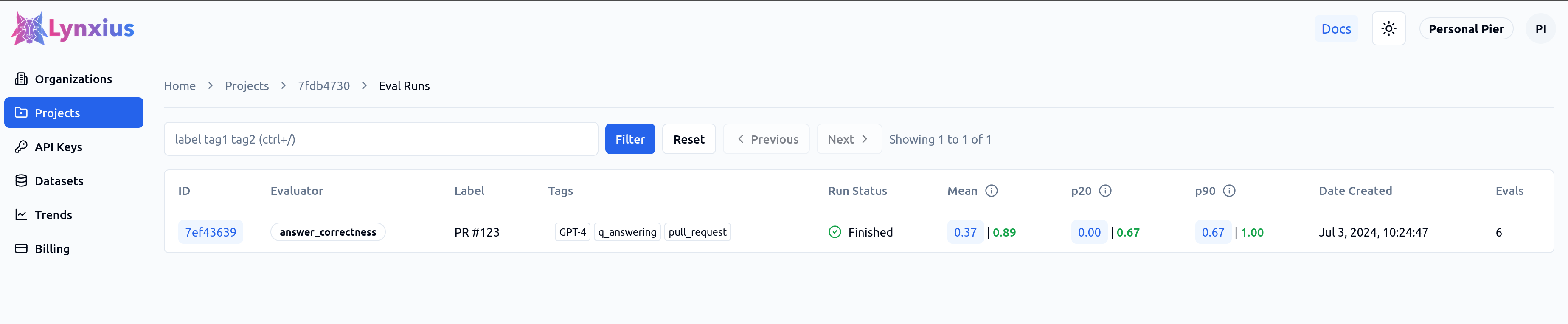
Score comparisons are also visible on the Eval Run page. In the screenshot below, | 0.89 signals that the lates PR scores higher (0.89) than the Main-Branch Baseline (0.37) for the Answer Correctness metric.
Create Baseline Projects
Navigate to the Projects page and create two new projects, then navigate to the API Keys page and create a secret for each one of them. You can name your projects as below.
| Name | Purpose | API Key Name |
|---|---|---|
| CI/CD | Collects all the Evaluations' results triggered by opening a PR. | LYNXIUS_CI_CD_API_KEY |
| Main-Branch Baseline | Collects all the Evaluations' results triggered when you merge a PR to your main branch. |
LYNXIUS_MAIN_API_KEY |
Set Up main Branch Evaluations
In the root directory of your application, create a folder named lynxius_tests. In this quickstart, we will test the chat_pizza_qa() function, which handles the question-answer task of our LLM App. The metric we will use for evaluation is Answer Correctness.
eval_main_baseline.py is the script used to run Evaluations when a PR is merged to main.
# lynxius_tests/eval_main_baseline.py
from lynxius.client import LynxiusClient
from lynxius.evals.answer_correctness import AnswerCorrectness
client = LynxiusClient()
# Fetch the test set using the UUID on the Lynxius platform
dataset = client.get_dataset_details(dataset_id="6e83cec5-d8d3-4237-af9e-8d4b7c71a2ce")
label = "main_baseline_qa_task" # lable identifier of baseline QA task
tags = ["GPT-4", "q_answering", "main_branch"]
answer_correctness = AnswerCorrectness(label=label, tags=tags)
for entry in dataset:
answer_correctness.add_trace(
query=entry["query"],
reference=entry["reference"],
output=chat_pizza_qa(entry["query"]), # chat_pizza LLM call
context=[]
)
client.evaluate(answer_correctness)
# lynxius_tests/eval_main_baseline.py
from lynxius.client import LynxiusClient
from lynxius.evals.answer_correctness import AnswerCorrectness
client = LynxiusClient(run_local=True) # run evals locally
# Fetch the test set using the UUID on the Lynxius platform
dataset = client.get_dataset_details(dataset_id="6e83cec5-d8d3-4237-af9e-8d4b7c71a2ce")
label = "main_baseline_qa_task" # lable identifier of baseline QA task
tags = ["GPT-4", "q_answering", "main_branch"]
answer_correctness = AnswerCorrectness(label=label, tags=tags)
for entry in dataset:
answer_correctness.add_trace(
query=entry["query"],
reference=entry["reference"],
output=chat_pizza_qa(entry["query"]), # chat_pizza LLM call
context=[]
)
client.evaluate(answer_correctness)
Now let's make sure that lynxius_tests/eval_main_baseline.py runs every time you merge to main with the .github/workflows/main_baseline.yml GitHub workflow below.
# .github/workflows/run_main_baseline.yml
name: Run Lynxius Evals on merge to main
on:
push:
branches:
- main
jobs:
evaluate-main-baseline:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Install dependencies
run: # Install all requirements needed to run chat_pizza_qa()
- name: Install Lynxius
run: |
python -m pip install --upgrade pip
pip install lynxius
- name: Set environment variables
run: echo "LYNXIUS_API_KEY=${{ secrets.LYNXIUS_MAIN_API_KEY }}" >> $GITHUB_ENV
- name: Run Lynxius evaluation
run: |
python lynxius_tests/eval_main_baseline.py
Compare New PRs with main Branch Baseline
eval_pull_request.py is the script used to run Evaluations when a PR is opened but not yet merged to the main branch. The script:
- Runs the same tests in
eval_main_baseline.pyand returns the Evaluations scores. - Fetches the latest scores from the Main-Branch Baseline project.
- Compares the scores of the PR with the Main-Branch Baseline ones. If the PR scores are lower than the baselines ones, the pipeline will fail.
# lynxius_tests/eval_pull_request.py
import sys
import argparse
from lynxius.client import LynxiusClient
from lynxius.evals.answer_correctness import AnswerCorrectness
# Define and parse command-line arguments
parser = argparse.ArgumentParser(description='Evaluate PR against Main Baseline')
parser.add_argument('--pr_number', type=int, required=True, help='Pull Request number')
parser.add_argument('--cicd_key', type=str, required=True, help='Lynxius CI/CD API key')
parser.add_argument('--baseline_key', type=str, required=True, help='Lynxius Baseline API key')
args = parser.parse_args()
pr_client = LynxiusClient(api_key=args.cicd_key)
bsl_client = LynxiusClient(api_key=args.baseline_key)
# Fetch the test set using the UUID on the Lynxius platform
dataset = pr_client.get_dataset_details(dataset_id="6e83cec5-d8d3-4237-af9e-8d4b7c71a2ce")
label = f"PR #{args.pr_number}"
tags = ["GPT-4", "q_answering", "pull_request"]
baseline_project_uuid="4d683adf-a17b-4847-bb78-9663152bcba7" # identifier of main baseline project
baseline_eval_run_label="main_baseline_qa_task" # lable identifier of baseline QA task
answer_correctness = AnswerCorrectness(
label=label,
tags=tags,
baseline_project_uuid=baseline_project_uuid,
baseline_eval_run_label=baseline_eval_run_label
)
for entry in dataset:
answer_correctness.add_trace(
query=entry["query"],
reference=entry["reference"],
output=chat_pizza_qa(entry["query"]), # chat_pizza LLM call
context=[]
)
# run eval
answer_correctness_uuid = pr_client.evaluate(answer_correctness)
# get eval results and compare
pr_eval_run = pr_client.get_eval_run(answer_correctness_uuid)
pr_score = pr_eval_run.get("aggregate_score")
bsl_score = bsl_client.get_eval_run(
pr_eval_run.get("baseline_eval_run_uuid")
).get("aggregate_score")
if pr_score > bsl_score:
print(f"PR score {pr_score} is greater than baseline score {bsl_score}.")
sys.exit(0)
else:
print(f"PR score {pr_score} is not greater than baseline score {bsl_score}.")
sys.exit(1)
# lynxius_tests/eval_pull_request.py
import sys
import argparse
from lynxius.client import LynxiusClient
from lynxius.evals.answer_correctness import AnswerCorrectness
# Define and parse command-line arguments
parser = argparse.ArgumentParser(description='Evaluate PR against Main Baseline')
parser.add_argument('--pr_number', type=int, required=True, help='Pull Request number')
parser.add_argument('--cicd_key', type=str, required=True, help='Lynxius CI/CD API key')
parser.add_argument('--baseline_key', type=str, required=True, help='Lynxius Baseline API key')
args = parser.parse_args()
pr_client = LynxiusClient(api_key=args.cicd_key, run_local=True) # run evals locally
bsl_client = LynxiusClient(api_key=args.baseline_key,run_local=True) # run evals locally
# Fetch the test set using the UUID on the Lynxius platform
dataset = pr_client.get_dataset_details(dataset_id="6e83cec5-d8d3-4237-af9e-8d4b7c71a2ce")
label = f"PR #{args.pr_number}"
tags = ["GPT-4", "q_answering", "pull_request"]
baseline_project_uuid="4d683adf-a17b-4847-bb78-9663152bcba7" # identifier of main baseline project
baseline_eval_run_label="main_baseline_qa_task" # lable identifier of baseline QA task
answer_correctness = AnswerCorrectness(
label=label,
tags=tags,
baseline_project_uuid=baseline_project_uuid,
baseline_eval_run_label=baseline_eval_run_label
)
for entry in dataset:
answer_correctness.add_trace(
query=entry["query"],
reference=entry["reference"],
output=chat_pizza_qa(entry["query"]), # chat_pizza LLM call
context=[]
)
# run eval
answer_correctness_uuid = pr_client.evaluate(answer_correctness)
# get eval results and compare
pr_eval_run = pr_client.get_eval_run(answer_correctness_uuid)
pr_score = pr_eval_run.get("aggregate_score")
bsl_score = bsl_client.get_eval_run(
pr_eval_run.get("baseline_eval_run_uuid")
).get("aggregate_score")
if pr_score > bsl_score:
print(f"PR score {pr_score} is greater than baseline score {bsl_score}.")
sys.exit(0)
else:
print(f"PR score {pr_score} is not greater than baseline score {bsl_score}.")
sys.exit(1)
Now let's make sure that lynxius_tests/eval_pull_request.py runs every time a new PR is opened against the main branch with the .github/workflows/pull_request.yml GitHub workflow below.
name: Run Lynxius Evals to compare PR with Main Baseline
on:
pull_request:
branches:
- main
jobs:
evaluate-pr-against-baseline:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Install dependencies
run: # Install all requirements needed to run chat_pizza_qa()
- name: Install Lynxius
run: |
python -m pip install --upgrade pip
pip install lynxius
- name: Run Lynxius evaluation
run: |
python lynxius_tests/eval_pr_baseline.py \
--pr_number ${{ github.event.pull_request.number }} \
--cicd_key ${{ secrets.LYNXIUS_CI_CD_API_KEY }} \
--baseline_key ${{ secrets.LYNXIUS_MAIN_API_KEY }}
Conclusion
By implementing this automated pipeline with Lynxius, you ensure that every PR is rigorously evaluated against your Main-Branch Baseline. This continuous assessment empowers you to confidently decide whether new code changes should be merged into the main branch, maintaining the highest standards of performance and reliability for your LLM App. Embrace this streamlined workflow to catch issues early, optimize development, and ship AI with unprecedented confidence and precision.