Semantic Similarity
Semantic Similarity evaluates the similarity between two pieces of text, making it ideal for tasks like paraphrase detection, text similarity analysis, information retrieval, and question answering. It computes a similarity score between the candidate sentence (generated text) and the reference (ground truth) sentence using embeddings generated with a Text Embedding Model. This approach captures the semantic meaning of the text, unlike traditional metrics that rely on exact matches.
Calculation
The Semantic Similarity computation involves the following steps:
- Embedding Extraction: Extract embeddings for the
outputandreferencesentences. - Similarity Calculation: Compute the cosine similarity1 between the embeddings of the
referenceandoutputsentences. This is done by taking the dot product of the two embedding vectors and dividing by the product of their norms. - Clamping: Ensure the cosine similarity value is in the range [0.0, 1.0]. In practice, embeddings produced by language models tend to have non-negative cosine similarity due to training techniques, but any negative values are clamped to 0.0.
The formula for cosine similarity \(S\) is as follows:
where:
- \(\vec{v1}\) is the embedding vector for the
referencetext. - \(\vec{v2}\) is the embedding vector for the
outputtext. - \(\vec{v1} \cdot \vec{v2}\) is the dot product of the two vectors.
- \(\|\vec{v1}\|\) and \(\|\vec{v2}\|\) are the norms of the vectors \(\vec{v1}\) and \(\vec{v2}\), respectively.
Example
Tip
Please consult our full Swagger API documentation to run this evaluator via APIs.
from lynxius.client import LynxiusClient
from lynxius.evals.semantic_similarity import SemanticSimilarity
client = LynxiusClient()
# add tags for frontend filtering
label = "PR #111"
tags = ["GPT-4", "chat_pizza", "info_retrieval", "PROD", "Pizza-DB:v2"]
semantic_similarity = SemanticSimilarity(label=label, tags=tags)
semantic_similarity.add_trace(
# reference from Wikipedia (https://github.com/lynxius/lynxius-docs/blob/main/docs/public/images/quattro_stagioni_wikipedia_reference.png)
reference=(
"Pizza quattro stagioni ('four seasons pizza') is a variety of pizza "
"in Italian cuisine that is prepared in four sections with diverse "
"ingredients, with each section representing one season of the year. "
"Artichokes represent spring, tomatoes or basil represent summer, "
"mushrooms represent autumn and the ham, prosciutto or olives represent "
"winter."
),
# output from OpenAI GPT-4 (https://github.com/lynxius/lynxius-docs/blob/main/docs/public/images/quattro_stagioni_gpt4_output.png)
output=(
"Pizza Quattro Stagioni is an Italian pizza that represents the four "
"seasons through its toppings, divided into four sections. Each section "
"features ingredients typical of a particular season, like artichokes "
"for spring, peppers for summer, mushrooms for autumn, and olives or "
"prosciutto for winter."
)
)
client.evaluate(semantic_similarity)
Click on the Eval Run link of your project to explore the output of your evaluation. Result UI Screenshot tab below shows the result on the UI, while the Result Values provides an explanation.
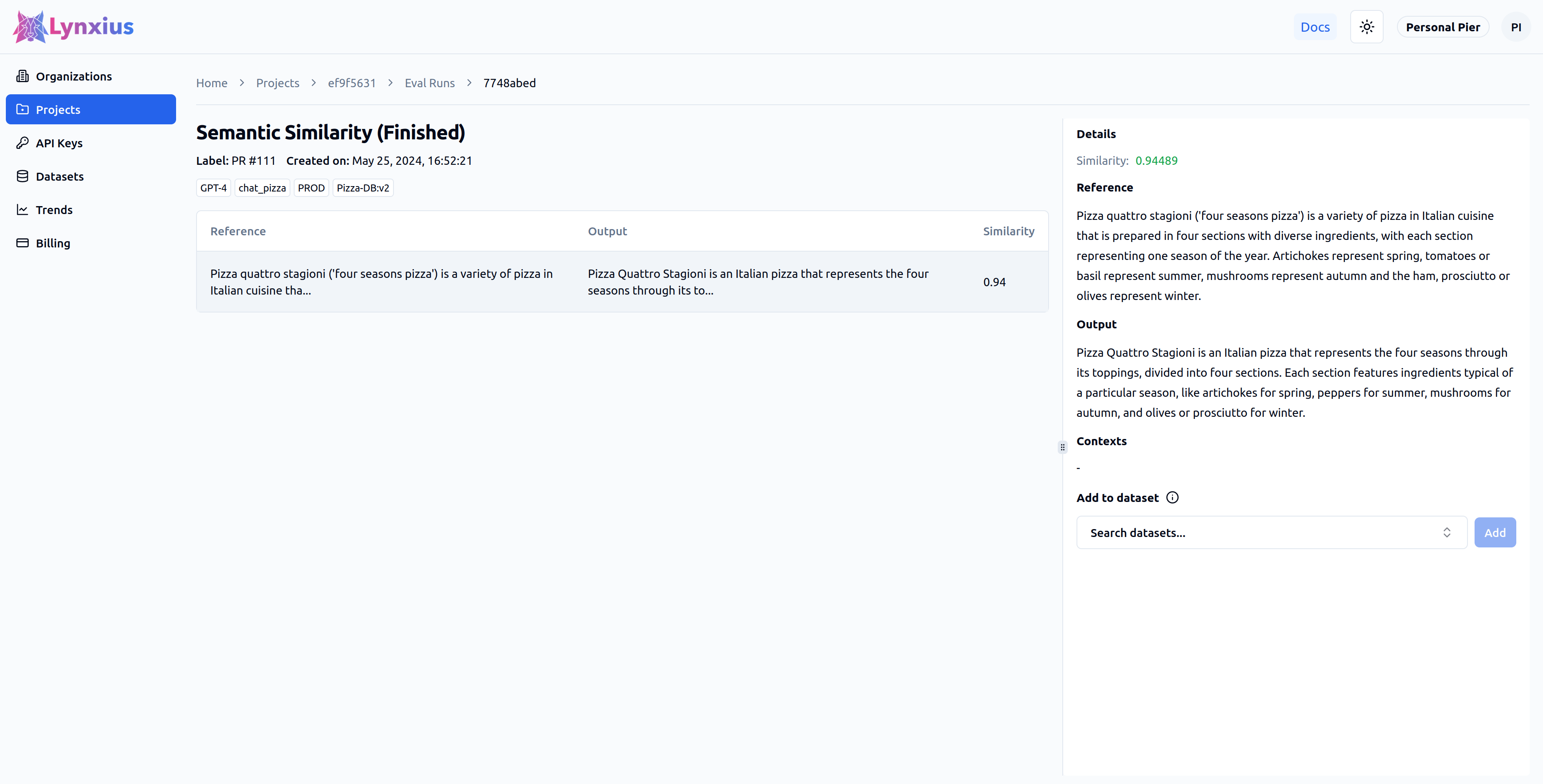
| Score | Value | Interpretation |
|---|---|---|
| Similarity | 0.94489 | The output is semantically similar to the reference, despite the output is only partially correct (see Answer Correctness). |
Inputs & Outputs
| Args | |
|---|---|
| label | A str that represents the current Eval Run. This is ideally the number of the pull request that run the evaluator. |
| href | A str representing a URL that gets associated to the label on the Lynxius platform. This ideally points to the pull request that run the evaluator. |
| tags | A list[str] of tags for filtering on UI Eval Runs. |
| data | An instance of ReferenceOutputPair. |
| Returns | |
|---|---|
| uuid | The UUID of this Eval Run. |
| similarity | A float in the range [0.0, 1.0] that quantifies the semantic similarity between the reference and output sentences. It is calculated using the cosine similarity between their respective embedding vectors. A score of 1.0 indicates perfect semantic alignment, while a score of 0.0 indicates no semantic similarity. |
-
‘Cosine similarity’ (2024) Wikipedia. Available at: https://en.wikipedia.org/wiki/Cosine_similarity (Accessed: May 25, 2024) ↩