Context Precision
Context Precision, also known as Average Precision (AP) at K, evaluates the quality of ranking algorithms, making it ideal for tasks like information retrieval. It measures how well relevant context chunks are ranked higher than irrelevant ones in a given list, with respect to a given reference (ground truth) sentence. It considers the precision at each position in the ranked sequence of context chunks and calculates the average of these precision values, focusing on the positions of relevant context chunks.
Context Precision is particularly useful in scenarios where the relevance and order of retrieved items matters significantly, such as search engines, recommendation systems, and Retrieval Augmented Generation (RAG) applications. It ensures that relevant items are not only present in the retrieved set but are also ranked correctly.
Calculation
The calculation of Average Precision at K \(\text{AP@K}\) involves summing the precision values at each rank position where a relevant item appears and then averaging these values. This method penalizes lower-ranked relevant items, ensuring that higher scores are awarded to rankings where relevant items are positioned at the top. To achieve a high \(\text{AP@K}\) score, all relevant items should be ranked as close to the top as possible, thereby improving the overall relevance and usefulness of the retrieved results.
Its computation involves the following steps:
- For every chunk provided in the
contextslist, compute a verdict. 1 means relevant, while 0 means not relevant to thereferencesentence. - Calculate \(N\) as the sum af all the verdicts. This is the total number of relevant chunks in the top-\(K\) results.
-
Calculate Precision at k \(\text{Precision@k}\) for all the top-\(k\) recommendations.
While Precision at k evaluates the share of relevant results in the top-\(k\) recommendations, it does not take into account their order. Average Precision (AP) at K helps addressing this.
-
Compute the Average Precision at K \(\text{AP@K}\).
The formulas for Precision at k \(\text{Precision@k}\) and Average Precision at K \(\text{AP@K}\) are as follows:
where:
- \(k\) is the \(k\)-th list of top-\(k\) input chuks.
- \(K\) is the full list of input chunks in
contexts(contains \(K\) chunks). - \(N\) is the total number of relevant chunks in the top-\(K\) results.
- \(v_k\) (the verdict) equals to 1 if the chunk at position \(k\) is relevant and 0 otherwise.
Example
Tip
Please consult our full Swagger API documentation to run this evaluator via APIs.
from lynxius.client import LynxiusClient
from lynxius.evals.context_precision import ContextPrecision
from lynxius.rag.types import ContextChunk
# We used LlamaIndex to rank our Wikipedia texts based on the `query` below
# reference from Wikipedia (https://github.com/lynxius/lynxius-docs/blob/main/docs/public/images/llamaindex_pizza_top4_rank.png)
context = [
ContextChunk(
document="Pizza marinara, also known as pizza alla marinara, is a style of pizza in Neapolitan cuisine seasoned with only tomato sauce, extra virgin olive oil, oregano and garlic. It is supposedly the oldest tomato-topped pizza.",
relevance=0.8461458079746771
),
ContextChunk(
document="Neapolitan pizza (Italian: pizza napoletana; Neapolitan: pizza napulitana), also known as Naples-style pizza, is a style of pizza made with tomatoes and mozzarella cheese. The tomatoes must be either San Marzano tomatoes or pomodorini del Piennolo del Vesuvio, which grow on the volcanic plains to the south of Mount Vesuvius.",
relevance=0.8450720279096852
),
ContextChunk(
document="Pizza quattro stagioni ('four seasons pizza') is a variety of pizza in Italian cuisine that is prepared in four sections with diverse ingredients, with each section representing one season of the year. Artichokes represent spring, tomatoes or basil represent summer, mushrooms represent autumn and the ham, prosciutto or olives represent winter.",
relevance=0.7993399980232716
),
ContextChunk(
document="The first pizzeria in the U.S. was opened in New York City's Little Italy in 1905. Common toppings for pizza in the United States include anchovies, ground beef, chicken, ham, mushrooms, olives, onions, peppers, pepperoni, salami, sausage, spinach, steak, and tomatoes.",
relevance=0.7988321996271018
)
]
client = LynxiusClient()
# add tags for frontend filtering
label = "PR #111"
tags = ["GPT-4", "chat_pizza", "info_retrieval", "PROD", "Pizza-DB:v2"]
context_precision = ContextPrecision(label=label, tags=tags)
context_precision.add_trace(
query="Which tomato sauce is used in neapolitan pizza? Keep it short.",
# reference from Wikipedia (https://github.com/lynxius/lynxius-docs/blob/main/docs/public/images/san_marzano_wikipedia_reference.png)
reference=(
"The tomato sauce of Neapolitan pizza must be made with San Marzano "
"tomatoes or pomodorini del Piennolo del Vesuvio."
),
context=context
)
client.evaluate(context_precision)
Click on the Eval Run link of your project to explore the output of your evaluation. Result UI Screenshot tab below shows the result on the UI, while the Result Values provides an explanation.
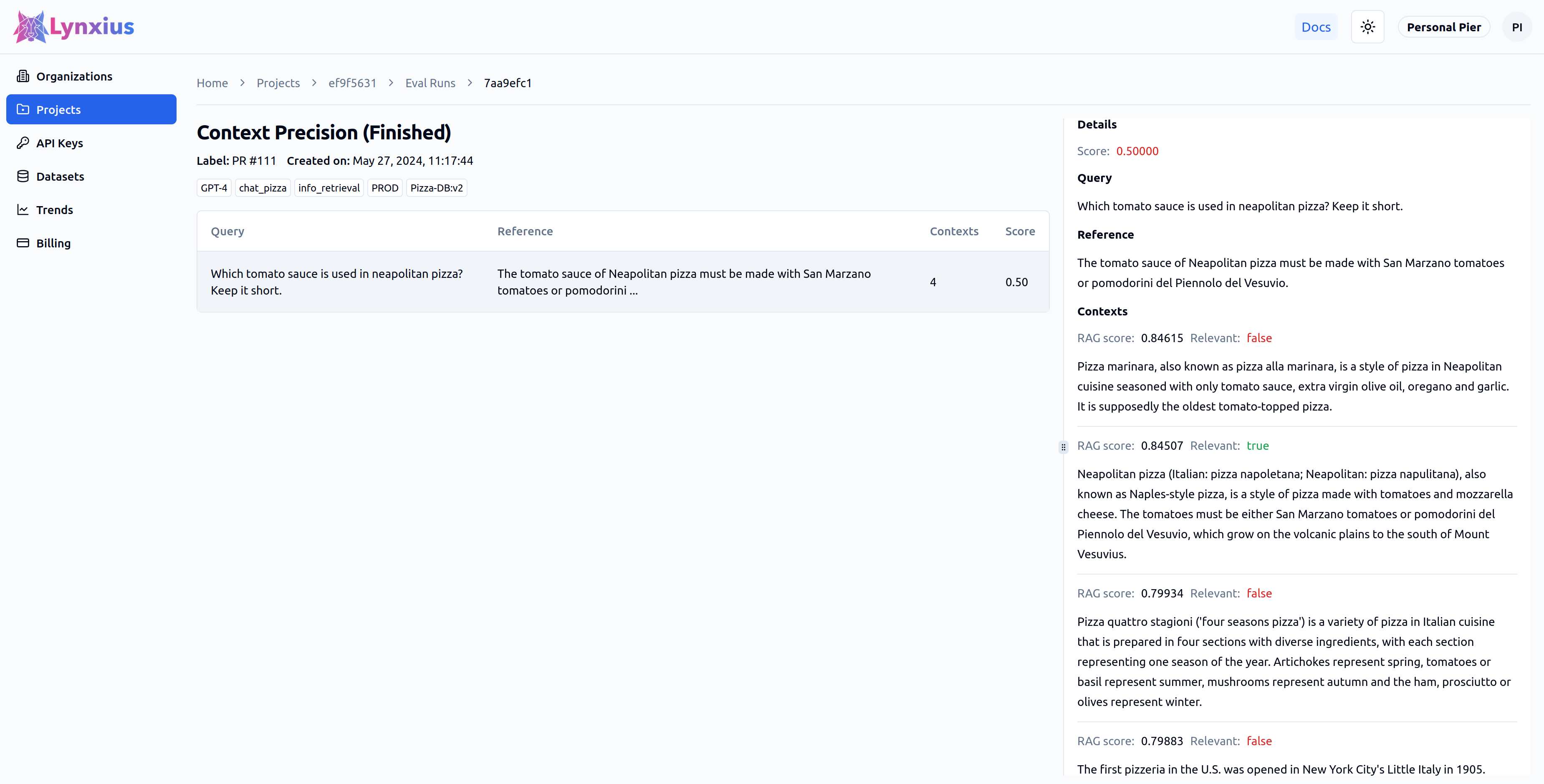
| Score | Value | Interpretation |
|---|---|---|
| Score | 0.50000 | The contexts are not very precise with respect to the reference because the only relevant chunk is ranked in the second position. |
| Relevant |
|
Only the relevance verdic of the second input chunk is True, while the rest are False. It seems like the input chunks were not ranked in the most optimal order (at least for the first two results). |
Inputs & Outputs
| Args | |
|---|---|
| label | A str that represents the current Eval Run. This is ideally the number of the pull request that run the evaluator. |
| href | A str representing a URL that gets associated to the label on the Lynxius platform. This ideally points to the pull request that run the evaluator. |
| tags | A list[str] of tags for filtering on UI Eval Runs. |
| data | An instance of QueryReferenceContextsTriplet. |
| Returns | |
|---|---|
| uuid | The UUID of this Eval Run. |
| score | A float in the range [0.0, 1.0] that quantifies the context precision between the input contexts and the reference sentences. It is calculated using the Average Precision (AP) at K. A score of 1.0 indicates perfect context precision, while a score of 0.0 indicates no context precision. |
| verdicts | A list[bool] of verdicts of same size of the contexts input list. The verdic at position \(k\) is True if the respective context chunk at position \(k\) in contexts is relevant with respect to the reference, and it is False otherwise. |