Evaluation
LLM Evaluation is the process of measuring the performance of an LLM application. In the context of LLMs, performance can be determined by a moltitude of metrics that we call Evaluators. Examples include: answer correctness, BERTScore, answer completeness, factuality and context precision. Each metric takes one or multiple inputs and returns a score with an explanation.
Evaluation Building Blocks
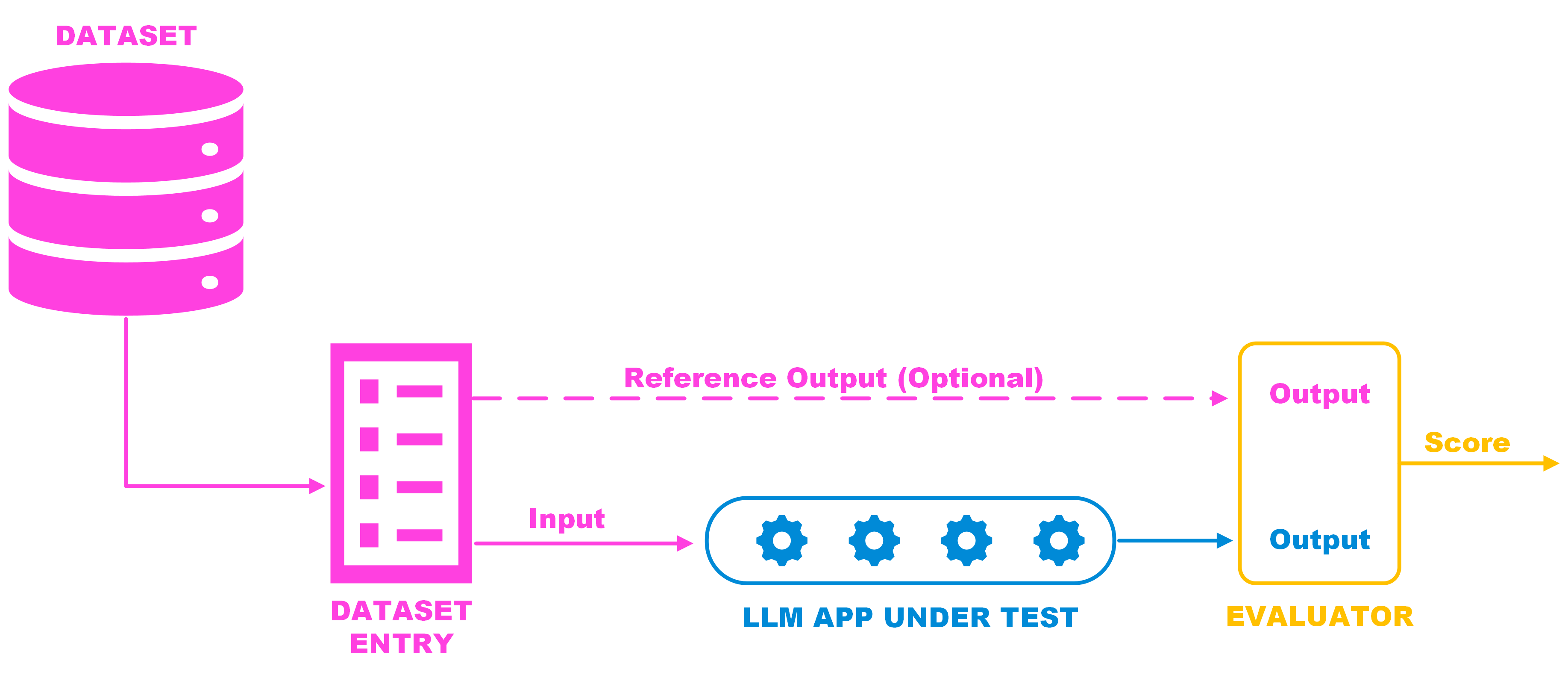
Why LLM Evaluation is Important
When developing using LLMs, understanding how code changes impact system performance is not trivial. LLMs return probabilistic output, making testing and debugging feel like guesswork without proper tools. Lynxius solves this by offering an Evaluation framework and a set of Evaluators to use as metrics.
With Lynxius you can:
- Use Baseline Comparisons to automatically detect if your latest code changes improve your LLM app's performance before merging them into the main branch.
- Use percentiles to understand how many edge cases have beein identifed during testing.
- Use Tags to compare prompt versions and identify the best one according to some metrics.
- Use Tags to which LLM models returns the best outputs for you LLM App.
Bulk Evaluations
LLMs are probabilistic, so it is good practice to run Evaluators over large datasets comprising multiple edge cases. Lynxius Bulk Evaluations enables you to run one or multiple Evaluators over all the entries of a dataset with a single command.
To boost usability, Lynxius can store users' Datasets, allowing them to be fetched to run Bulk Evaluations with a single command. Using the Datasets feature is as easy as uploading a CSV file (as described in Upload CSV), while fetching the dataset is a single line of command:
from lynxius.client import LynxiusClient
client = LynxiusClient(run_local=True)
# Download a dataset previously uploaded to the Lynxius Platform
dataset_details = client.get_dataset_details(dataset_id="YOUR_DATASET_UUID")