BERTScore
BERTScore, introduced by Zhang, Tianyi, et al.1, evaluates text generation quality, making it ideal for tasks like text summarization and machine translation. It computes a similarity score for each token in the candidate sentence (generated text) with each token in the reference (ground truth) sentence. Instead of exact matches, token similarity is computed using embeddings generated with a Text Embedding Model. In this way the context in which words appear is taken into consideration, unlike with traditional metrics like BLEU or ROUGE, which rely on n-gram overlap and can be limited in capturing semantic meaning.
Calculation
The BERTScore computation involves the following steps:
- Embedding Extraction: Extract embeddings for each word (or sentence) token in the
outputandreference. - Similarity Calculation: Compute the cosine similarity between each word (or sentence) token embedding in the
outputand each word (or sentence) token embedding in thereference. - Matching Tokens: For each word (or sentence) token in the
output, find the highest similarity score with any word (or sentence) token in thereference(precision). Similarly, for each word (or sentence) token in thereference, find the highest similarity score with any word (or sentence) token in theoutput(recall).
The formulas for precision \(P\), recall \(R\), and F1 score \(F1\) are as follows:
where:
- \(c\) is the set of embeddings for the
outputword (or sentence) tokens. - \(r\) is the set of embeddings for the
referenceword (or sentence) tokens. - \(sim(x,y)\) is the cosine similarity between embeddings \(x\) and \(y\).
Example
Tip
Please consult our full Swagger API documentation to run this evaluator via APIs.
from lynxius.client import LynxiusClient
from lynxius.evals.bert_score import BertScore
client = LynxiusClient()
# add tags for frontend filtering
label = "PR #111"
tags = ["GPT-4", "chat_pizza", "summarization", "PROD", "Pizza-DB:v2"]
bert_score = BertScore(
label=label,
tags=tags,
level="word",
presence_threshold=0.55
)
bert_score.add_trace(
# reference from Wikipedia (https://github.com/lynxius/lynxius-docs/blob/main/docs/public/images/san_marzano_wikipedia_reference.png)
reference=(
"The tomato sauce of Neapolitan pizza must be made with San Marzano "
"tomatoes or pomodorini del Piennolo del Vesuvio."
),
# output from OpenAI GPT-4 (https://github.com/lynxius/lynxius-docs/blob/main/docs/public/images/san_marzano_gpt4_output.png)
output=(
"San Marzano tomatoes are traditionally used in Neapolitan pizza sauce."
)
)
client.evaluate(bert_score)
Click on the Eval Run link of your project to explore the output of your evaluation. Result UI Screenshot tab below shows the result on the UI, while the Result Values provides an explanation.
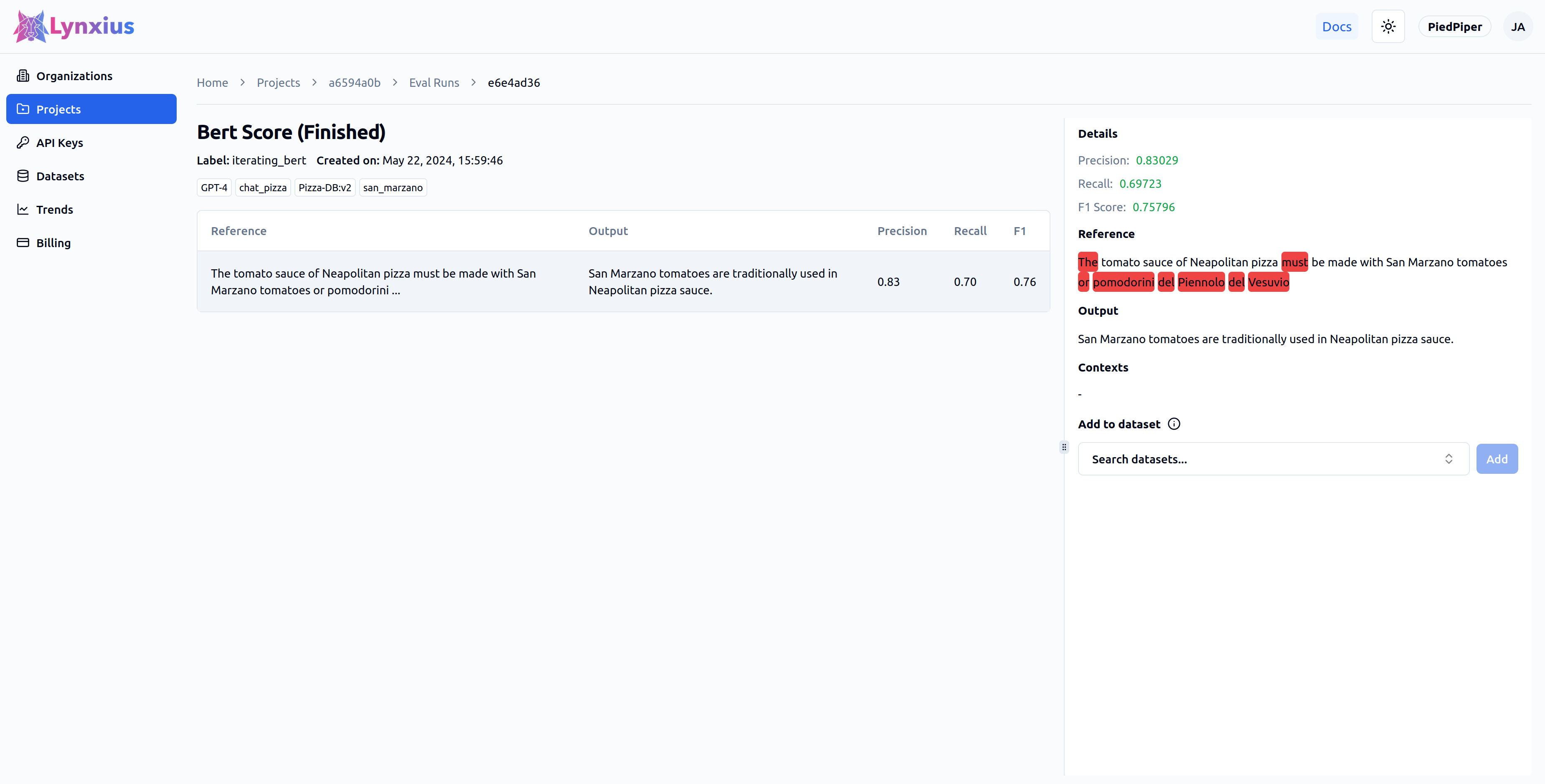
| Score | Value | Interpretation |
|---|---|---|
| Precision | 0.83029 | Many tokens in the output are similar to the reference text. |
| Recall | 0.69723 | A good part of the tokens in the reference are similar to the output text. |
| F1 Score | 0.75796 | Both precision and recall are good. |
| Missing Tokens | The tomato sauce of Neapolitan pizza must be made with San Marzano tomatoes or pomodorini del Piennolo del Vesuvio |
The words (or sentences) highlighted in red are present in the reference, but missing in the output. Comparisons in this example are based on words, as determined by the input argument level. |
Inputs & Outputs
| Args | |
|---|---|
| label | A str that represents the current Eval Run. This is ideally the number of the pull request that run the evaluator. |
| href | A str representing a URL that gets associated to the label on the Lynxius platform. This ideally points to the pull request that run the evaluator. |
| tags | A list[str] of tags for filtering on UI Eval Runs. |
| level | A str that can be any of [word | sentence]. word is used to identify words in the reference text with a similarity score below presence_threshold when compared to other words in the candidate text. sentence is used to identify entire sentences in the reference text with a similarity score below presence_threshold when compared to other sentences in the candidate text. |
| presence_threshold | Token comparisons between reference and output with similarity scores below this float threshold are returned among the missing_tokens. |
| data | An instance of ReferenceOutputPair. |
| Returns | |
|---|---|
| uuid | The UUID of this Eval Run. |
| precision | A float in the range [0.0, 1.0] that measures how many of the word (or sentence) tokens in the output are similar to any word (or sentence) token in the reference. Comparisons can be run based on words or sentences depending on the input argument level. A score of 1.0 indicates that all tokens in the output are perfectly similar to the reference, while a score of 0.0 indicates no tokens in the output are similar to the reference. |
| recall | A float in the range [0.0, 1.0] that measures how many of the word (or sentence) tokens in the reference are found in the output. Comparisons can be run based on words or sentences depending on the input argument level. A score of 1.0 indicates that all tokens in the reference are perfectly similar to the output, while a score of 0.0 indicates no tokens in the reference are similar to the output. |
| f1 | A float in the range [0.0, 1.0] that represents the overall similarity between the output and reference words (or sentences). Comparisons can be run based on words or sentences depending on the input argument level. A score of 1.0 indicates perfect overall similarity between output and reference, while a score of 0.0 indicates no overall similarity between output and reference. |
| missing_tokens | A list[tuple[int, int]] of token spans representing the word (or sentence) tokens in the reference text that are missing in the output text. A token in the reference that has similarity score below presence_threshold when compared to a token in the output is classified as missing in the output. A token span represents the start and end positions of the token within the reference text. Comparisons can be run based on words or sentences depending on the input argument level. |
-
Zhang, Tianyi, et al. "Bertscore: Evaluating text generation with bert." arXiv preprint arXiv:1904.09675 (2019). Available at: https://arxiv.org/abs/1904.09675 ↩