Answer Correctness
Info
Answer Correctness measures correctness and completeness of the generated answer.
Answer Correctness evaluates the accuracy of the generated answer when compared to the reference (ground truth) one, making it ideal for tasks like question answering. It returns a score from 0 to 1, with higher scores indicate better alignment, focusing on factual correctness. While our approach is inspired by Ragas1, it incorporates distinct methodologies.
Calculation
Factual correctness quantifies the factual overlap between the generated output and the reference ( ground truth) answer. This is done using the concepts of:
- TP (True Positive): Clauses or statements present in the generated
outputthat are also directly supported by one or more clauses or statements in thereference. - FP (False Positive): Clauses or statements present in the generated
outputbut not directly supported by any statement in thereference. - FN (False Negative): Clauses or statements present in the
referencebut not present in the generatedoutput.
The formulas for precision \(P\), recall \(R\), and F1 score \(F1\) are as follows:
Example
Tip
Please consult our full Swagger API documentation to run this evaluator via APIs.
from lynxius.client import LynxiusClient
from lynxius.evals.answer_correctness import AnswerCorrectness
client = LynxiusClient()
# add tags for frontend filtering
label = "PR #111"
tags = ["GPT-4", "chat_pizza", "q_answering", "PROD", "Pizza-DB:v2"]
answer_correctness = AnswerCorrectness(label=label, tags=tags)
answer_correctness.add_trace(
query="What is pizza quattro stagioni? Keep it short.",
# reference from Wikipedia (https://github.com/lynxius/lynxius-docs/blob/main/docs/public/images/quattro_stagioni_wikipedia_reference.png)
reference=(
"Pizza quattro stagioni ('four seasons pizza') is a variety of pizza "
"in Italian cuisine that is prepared in four sections with diverse "
"ingredients, with each section representing one season of the year. "
"Artichokes represent spring, tomatoes or basil represent summer, "
"mushrooms represent autumn and the ham, prosciutto or olives represent "
"winter."
),
# output from OpenAI GPT-4 (https://github.com/lynxius/lynxius-docs/blob/main/docs/public/images/quattro_stagioni_gpt4_output.png)
output=(
"Pizza Quattro Stagioni is an Italian pizza that represents the four "
"seasons through its toppings, divided into four sections. Each section "
"features ingredients typical of a particular season, like artichokes "
"for spring, peppers for summer, mushrooms for autumn, and olives or "
"prosciutto for winter."
)
)
client.evaluate(answer_correctness)
Click on the Eval Run link of your project to explore the output of your evaluation. Result UI Screenshot tab below shows the result on the UI, while the Result Values provides an explanation.
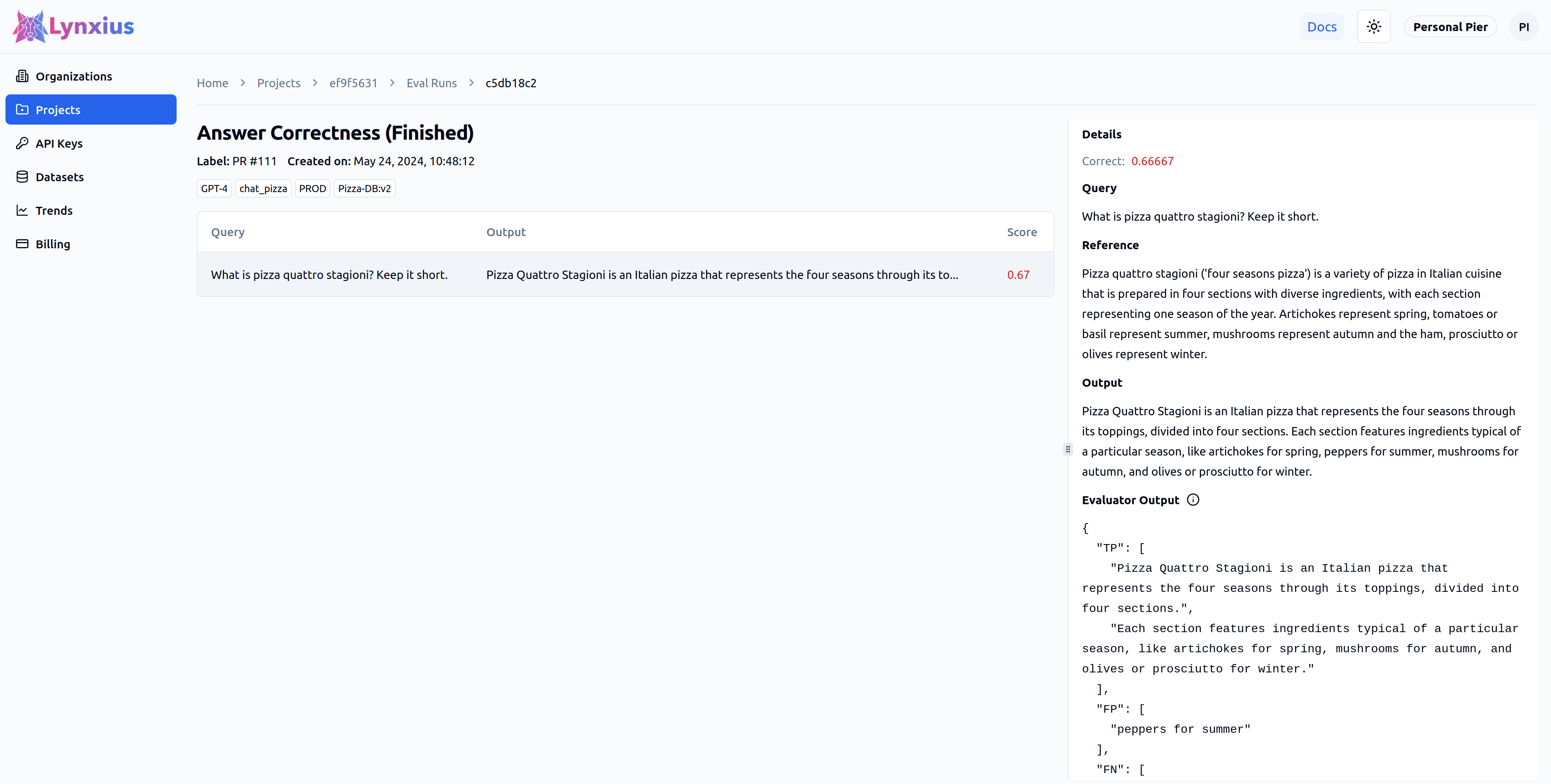
| Score | Value | Interpretation |
|---|---|---|
| Score | 0.66667 | The output is only partially correct when compared to the reference. |
| Evaluator Output |
|
Two True Positives, one False Positive and one False Negative have been detected. |
Inputs & Outputs
| Args | |
|---|---|
| label | A str that represents the current Eval Run. This is ideally the number of the pull request that run the evaluator. |
| href | A str representing a URL that gets associated to the label on the Lynxius platform. This ideally points to the pull request that run the evaluator. |
| tags | A list[str] of tags for filtering on UI Eval Runs. |
| data | An instance of QueryReferenceOutputTriplet. |
| Returns | |
|---|---|
| uuid | The UUID of this Eval Run. |
| precision | A float in the range [0.0, 1.0] that indicates how many of the retrieved clauses or statements are correct and complete. A score of 1.0 indicates that all retrieved clauses or statements in the output are correct and complete with respect to the reference, while a score of 0.0 indicates none of the retrieved clauses or statements in the output are correct and complete with respect to the reference. |
| recall | A float in the range [0.0, 1.0] that indicates how many relevant clauses or statements are retrieved. A score of 1.0 indicates that all relevant clauses or statements in the reference are retrieved in the output, while a score of 0.0 indicates none of the relevant clauses or statements in the reference are retrieved in the output. |
| f1 | A float in the range [0.0, 1.0] that represents the overall accuracy of the output compared to the reference. A score of 1.0 indicates perfect overall accuracy in the output compared to the reference, while a score of 0.0 indicates no overall accuracy in the output compared to the reference. |
-
‘Answer Correctness’ (2024) Ragas. Available at: https://docs.ragas.io/en/stable/concepts/metrics/answer_correctness.html (Accessed: May 24, 2024) ↩